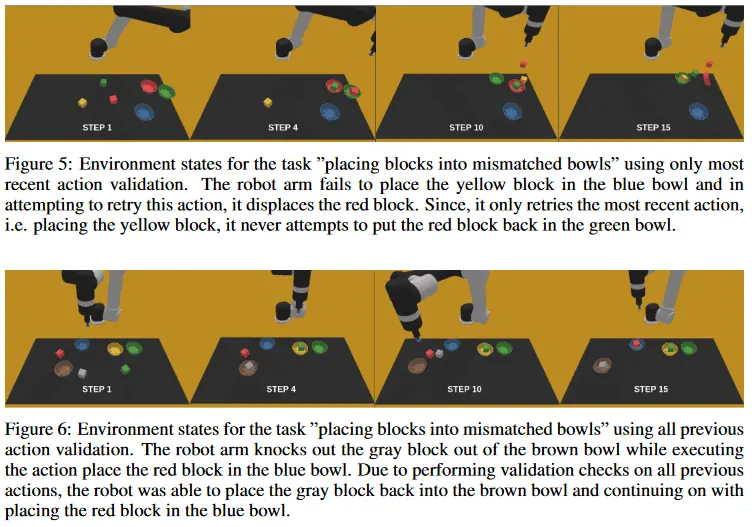
Introduction
This project was done as a class project for Deep Learning for Robotics class @Georgia Tech.
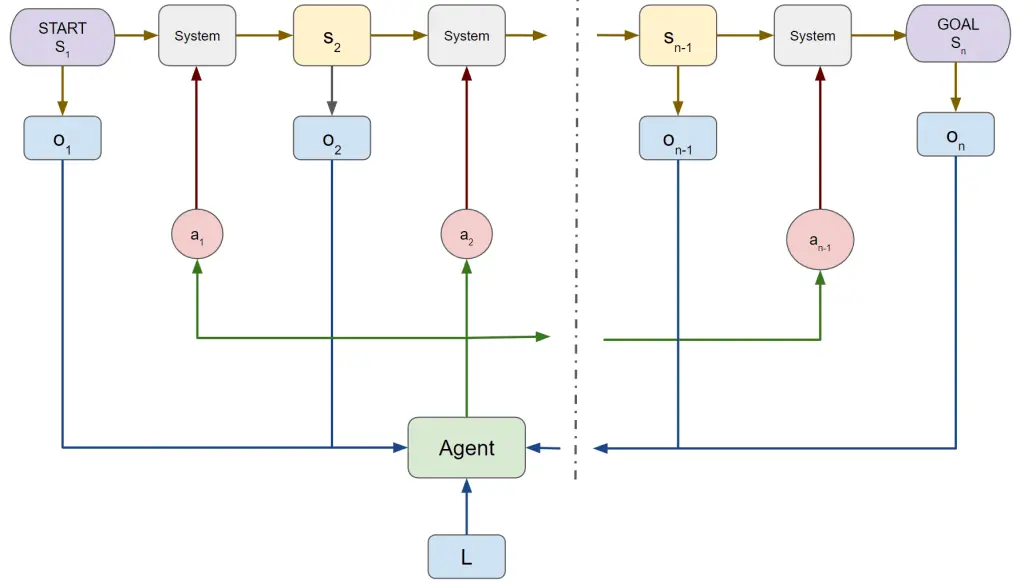
While humans naturally follow an act-see-reason-act paradigm, current robot planning approaches often lack the ability to incorporate feedback from actions and recover from failures. This sort of long horizon task planning is missing in robots.
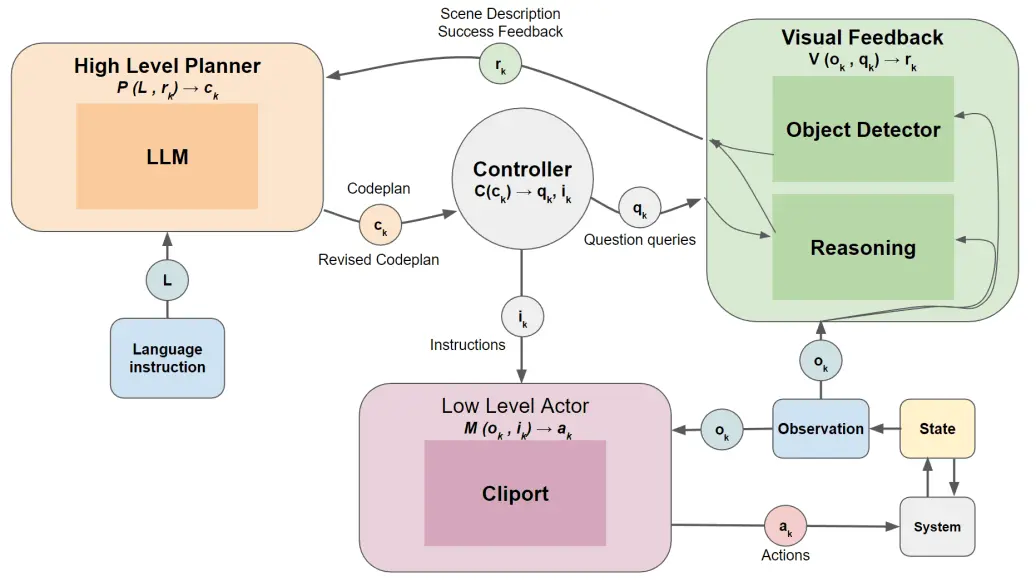
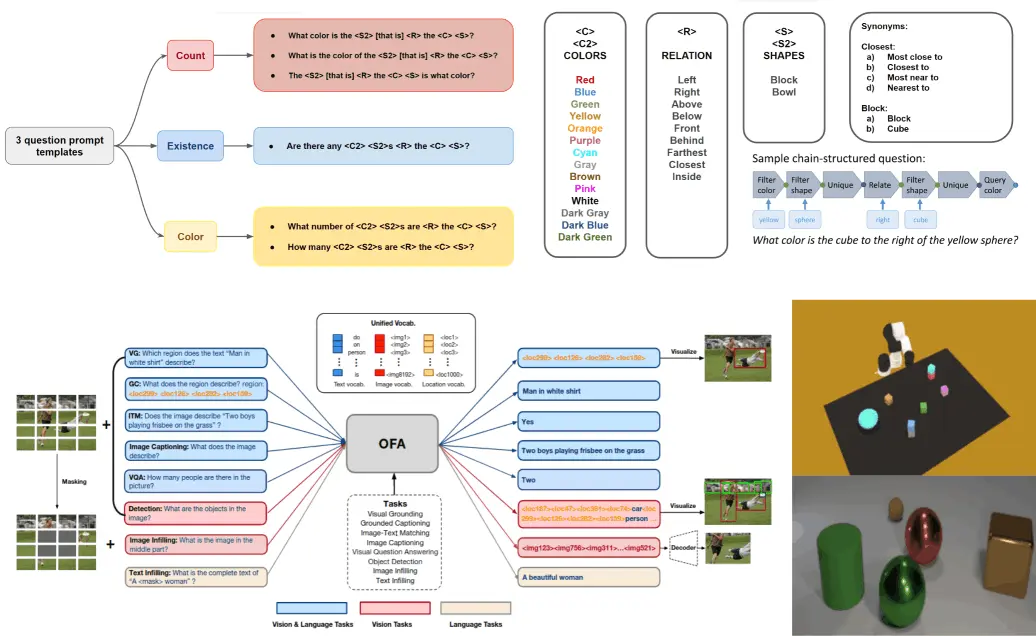
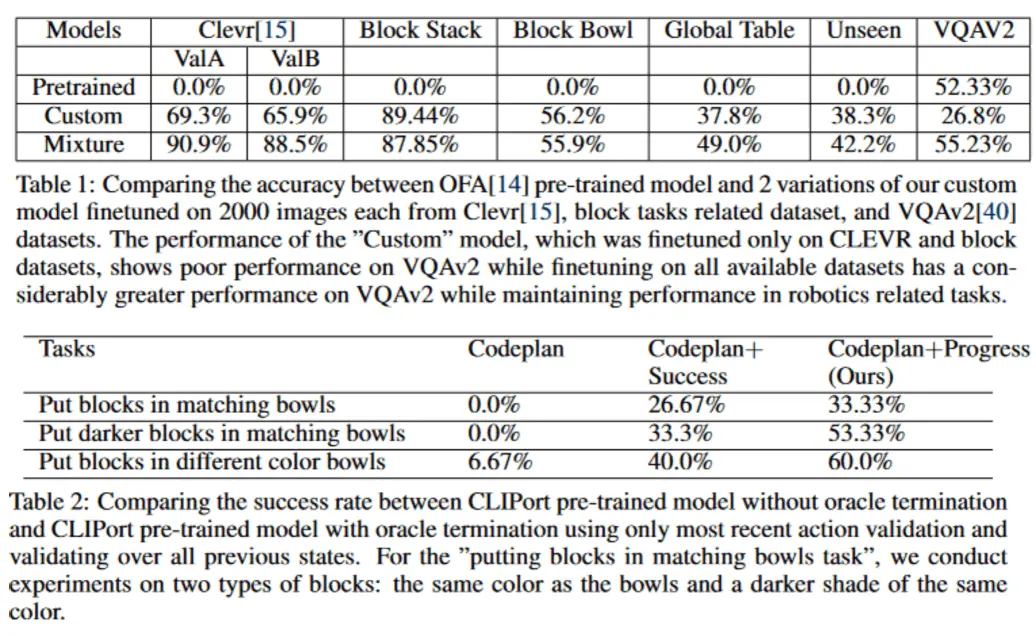
In this project, we propose a novel approach that combines large language models (LLMs) with a visual reasoning system (VRS) inspired by the human visual cortex.