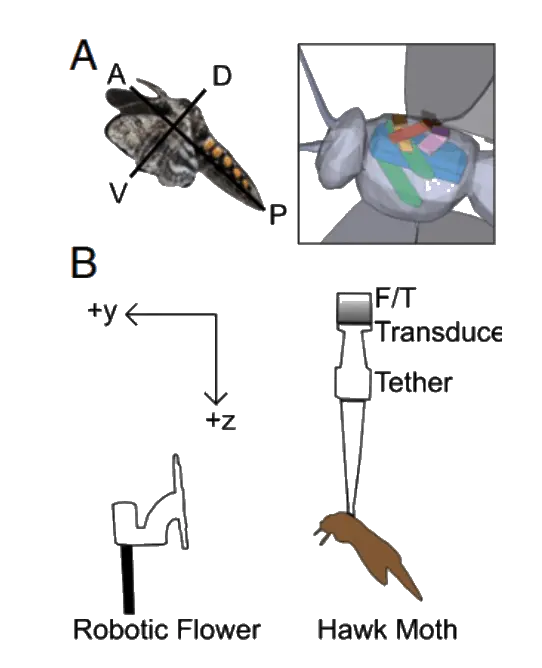
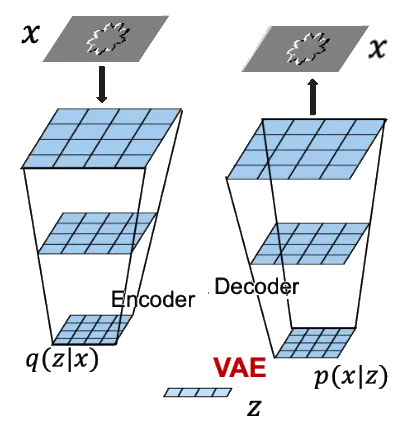
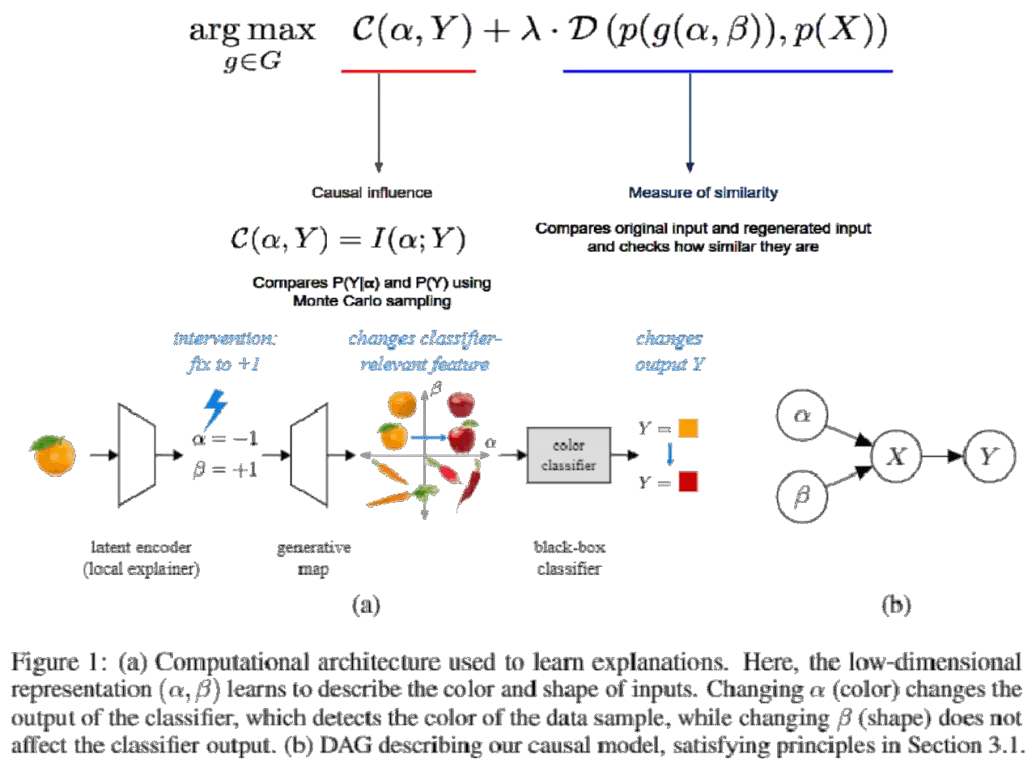
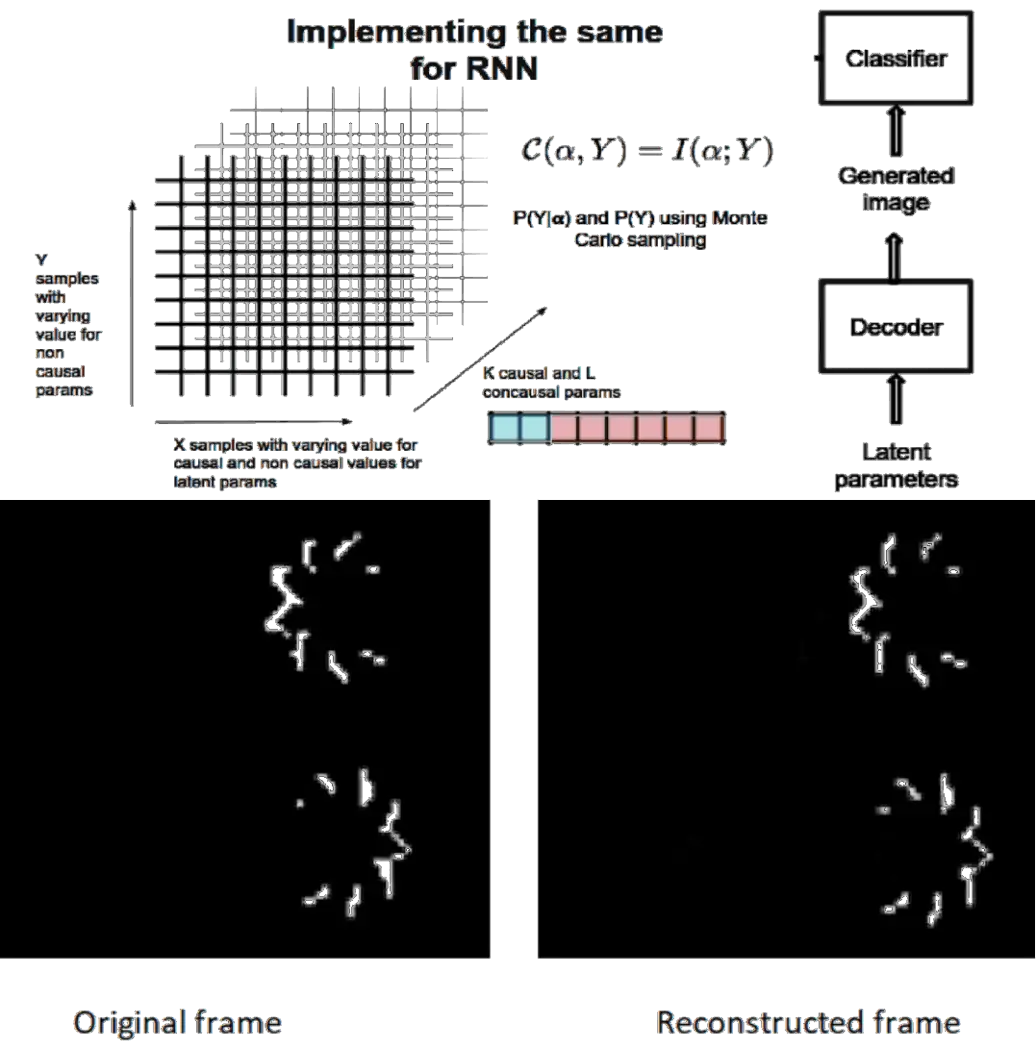
A normal VAE would use the loss function to measure the similarity between the input and output frames. This would ensure that the generated output is from the same gaussian as the one into which the input gets encoded. But in order to measure the causal influence of the factors in the latent space, we need to have a measure against which me measure causality. Thus the framework introduces the classifier (for which we want to find causal factors) at the end of the VAE decoder.
Later the same model was tested on the actual EPM frame sequence. First the training was done without the causal term as it wasn't obvious what should be the classification criteria for it. The results obtained were pretty satisfactory as the new frames generated were matching the original ones with just 8 latent parameters used.
But after this, there were many issues due to which the GCE framework could not be implemented on the data successfully.
The classifier for which we needed to find causal factors was the RNN. However, to find the causal factors, a large number of random samples are generated from the dataset.
Another major issue that was faced was the RNN had a regression output for the spike timings of the 44 different muscles. In the case of GCE, a binary output or a probability value for the digits was easily integrated into the framework. But a multi variable regression output required further researching into modelling the output as a gaussian distribution. Otherwise the classifier output could not be fed back into the network to find the causal term.