Introduction
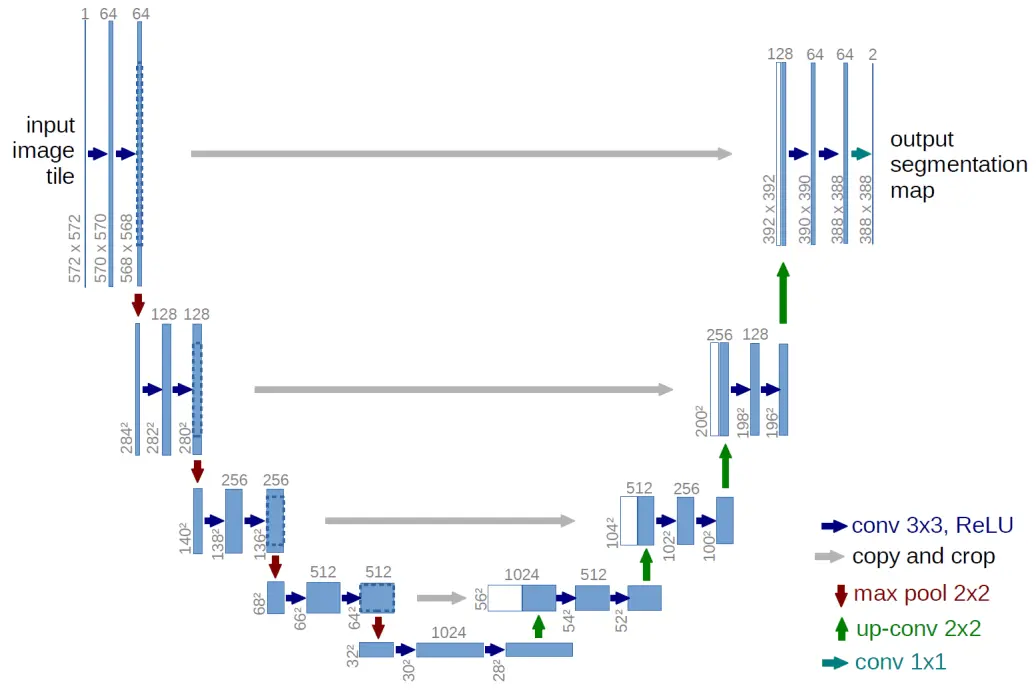
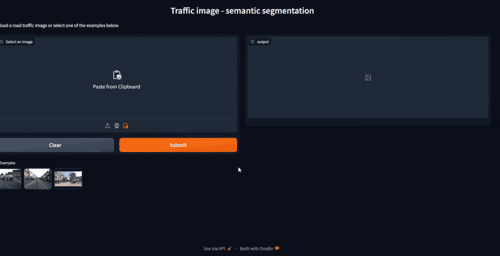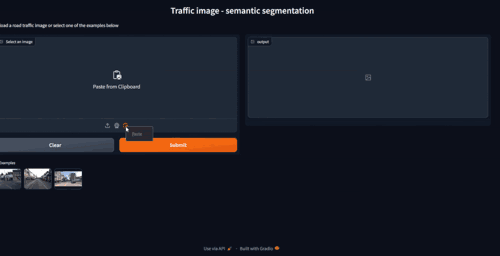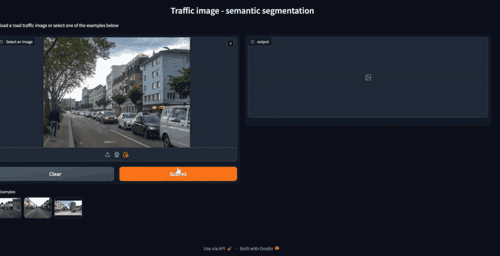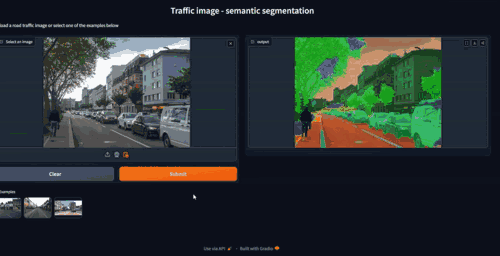
To perceive its environment, an autonomous vehicle relies on advanced sensors like lidars and cameras, which generate lots of raw data. However, this data must undergo extensive processing to derive meaningful semantic and spatial information. Existing image segmentation models perform well under clear conditions but severe weather degrades the quality of image data reducing their performance.
To counter the distortion of images, real-time and post processing techniques have been used to mitigate the effect of severe weather on these images without altering the scene. Additionally, ensembling multiple deep learning models has been shown to improve the accuracy of object detection in unfavorable weather conditions.