Work Done
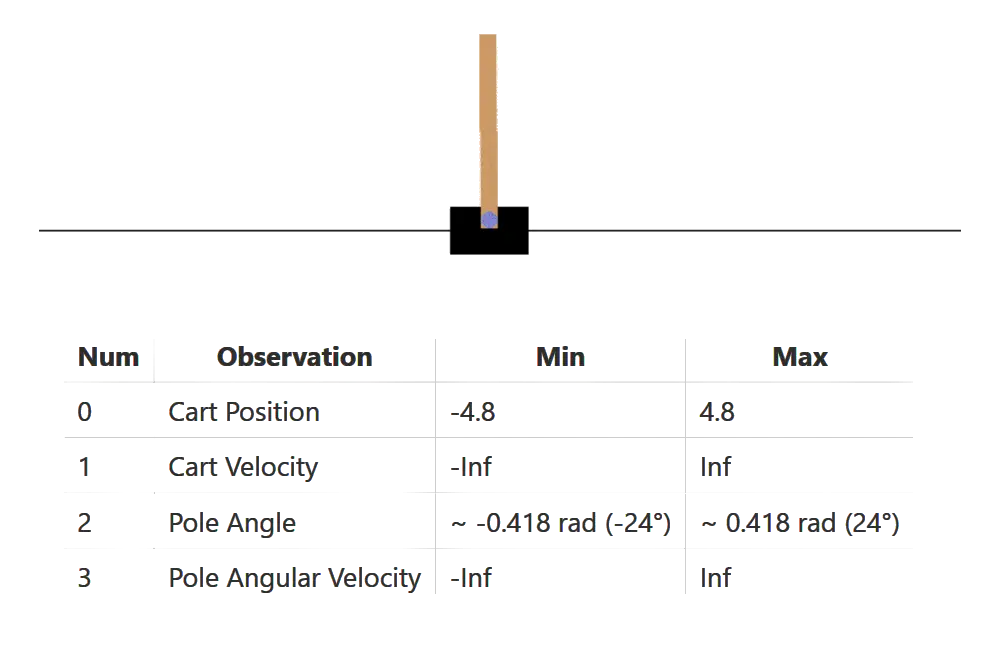
Score for the environment is measured by the time steps for which the pole was upright. The objective is to maximize this score.
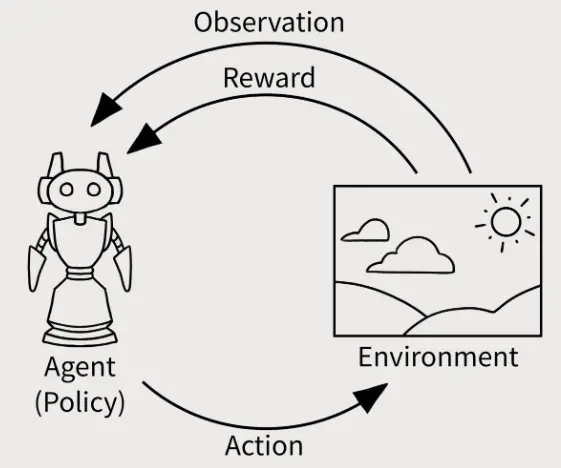
I decided to approach this problem by training a reinforcement learning controller that can learn as per a specific policy which either rewards or penalizes the agent based on pre set conditions.
In the initial few iterations, I randomized the controller input to check how much score I get for randomized input values. If the score was above a certain threshold value, I stored it in a separate list. The observation-action sequence for these scores was also stored in memory. These initial seeds give us supposedly good observation-action sequences that can lead to high scores.
The first random seed of iterations gave me a median score of 28 time steps. I stored the observation-action sequence for all above my threshold value of 20. This was to be used as training data for the model to train on.
Then I used tensorflow's TFLearn library to make a deep-learning neural network that could learn the mapping from the observations to the actions. This was modeled as a dense network of linear layers. The input layer was observations with 4 inputs. Output was actions layer with 2 outputs. In between there were 5 layers of 128, 256, 512, 256, 128 neurons respectively.
ReLu was the activation function for all layers except for the layer which used a soft-max activation. Categorical cross entropy loss was used as a cost function.